
Last Updated on July 7, 2026
By Florian Smeritschnig, former McKinsey Senior Consultant. Updated July 2026.
Can AI do consulting work? Not yet, at least not the whole job. The most rigorous test to date, Mercor’s 2026 APEX-Agents benchmark, dropped leading AI models into realistic consulting tasks and found that the best of them finished fewer than 25% correctly on the first try. AI can draft a slide and crunch a number.
What it cannot yet do is the end-to-end thing consulting actually sells: define the right question, dig the answer out of messy information, and deliver a recommendation that holds up. Here is what the data shows, and what it means if you are betting a career on this industry.
Key Takeaways
- In Mercor’s 2026 benchmark, top models (Gemini 3 Flash, GPT-5.2) completed under 25% of real consulting tasks correctly on the first attempt.
- Even with eight attempts per task, the best agent reached only about 40%.
- AI fails on the hard parts of consulting: ambiguity, finding facts across fragmented sources, and holding context over long, multi-step work.
- The verdict: AI augments consulting work; it does not yet replace the consultant who owns the outcome.
- For candidates, this is why judgment and structure, not polished output, still decide who gets hired.
Can AI Do Consulting Work? What the Evidence Says
The honest answer is that AI does tasks well and the job badly. It writes fluent text, builds passable slides, and speeds up analysis. Those are real gains. But a consulting engagement is not a stack of tasks; it is a single accountable chain from ambiguous problem to defensible recommendation, and that chain is where AI still falls apart.
Until recently this was opinion. Now there is data. Mercor, a research and expert-marketplace firm, built a benchmark specifically to test whether AI agents can do professional work like consulting, and the results are the clearest evidence yet that full autonomy is not close.
The rest of this article walks through what they did, what they found, and why it matters for your career.
The Study: How Mercor Tested AI on Real Consulting Tasks
Most AI benchmarks test isolated question-and-answer ability, which tells you little about whether a model can do a real job. Mercor’s APEX-Agents benchmark was built to fix that gap. Instead of quiz questions, it simulates the multi-step, long-horizon work professionals actually deliver.
The researchers surveyed hundreds of experts from top firms, then constructed data-rich “work environments” full of documents, spreadsheets, emails, and tool interactions that an agent has to work through to finish a task. In one consulting scenario, an agent might have to move through a file system of client reports, analyze consumption patterns, compute penetration metrics in a spreadsheet, and then write a concise summary of the insights.
These are not multiple-choice tests. They are the kind of messy, hours-long missions that make up real client work, which is exactly why the results are so telling. The full methodology is documented in the research paper.
The Results: AI Fails Most Real Consulting Tasks
When Mercor ran leading models against these scenarios, the scores were sobering. On a Pass@1 basis, meaning the output had to meet all the expert-defined criteria on the first try, the best models cleared fewer than 25% of tasks.
| Model | Pass@1 on consulting-style tasks (approx.) |
|---|---|
| Gemini 3 Flash | ~24% |
| GPT-5.2 | ~23% |
| Claude Opus 4.5 / Gemini 3 Pro | ~18% |
| GPT-5 | ~18% |
| Grok 4 | ~15% |
| GPT-OSS-120B / Kimi K2 Thinking | under 5% |
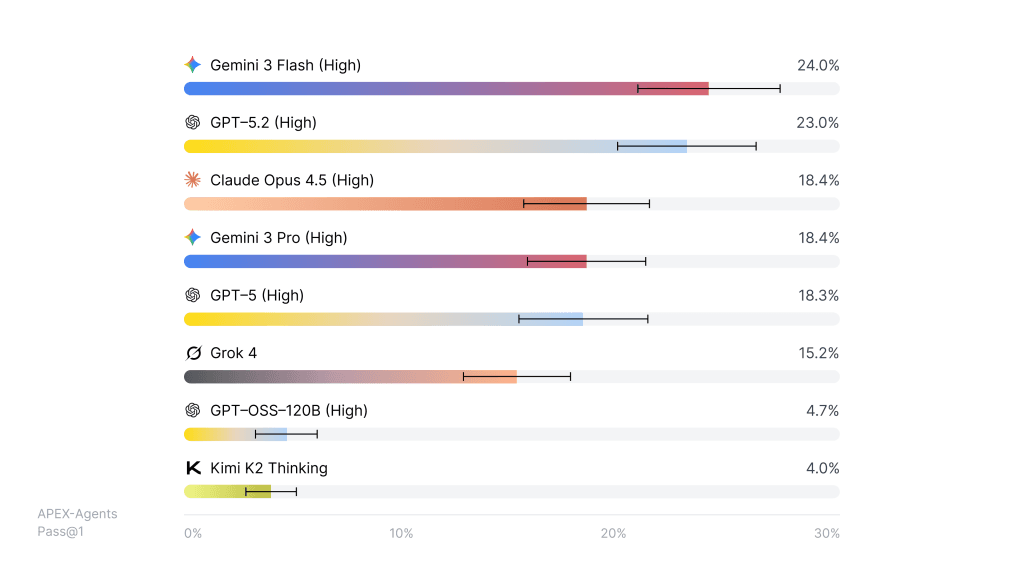
Even when agents were given eight attempts per task, the best success rate rose only to about 40%. In plain terms: on work built to mirror real consulting, state-of-the-art AI fails roughly three out of four times unaided, and still fails the majority even with retries. This is not a knock on the models’ intelligence. It is a statement about how hard the actual job is.
Why AI Falls Short on Consulting Work
The failure is not about writing or math, which AI handles well. It is about the shape of consulting work. Mercor’s results pinpoint exactly where agents break down, and every weakness maps to something a consultant does every day.
- Managing ambiguity. Real problems arrive underspecified. Deciding what the actual question is takes judgment, not retrieval.
- Finding the signal in fragmented information. The relevant fact is buried across mismatched files, formats, and sources. Agents struggle to hunt it down and know it matters.
- Holding context over long, multi-step work. Consulting is a chain of decisions where each step depends on the last. Agents lose the thread over long horizons.
Here is what that looks like in practice. Give an agent a folder of client reports and ask for the three insights that matter, and it will often summarize the wrong documents, miss the number buried in a footnote, and hand back a confident, clean answer that a partner would reject in ten seconds. The output looks like consulting. It just is not right, and knowing the difference is the job.
Put those together and you get the core reason AI can assist but not replace: consulting is an end-to-end process of framing, prioritizing, synthesizing, and standing behind a call. AI is strong at the pieces and weak at owning the whole. When I look at AI output, it reminds me of a polished consulting case interview candidate who cannot defend their own structure.
It looks right until you push on it.
What AI Is Good At vs. What It Can’t Do
For a candidate, the useful takeaway is the split. Knowing which side of the line a task sits on is exactly the judgment firms now test for.
| AI does this well | AI can’t reliably do this |
|---|---|
| Draft slides, memos, and summaries | Frame the right problem from ambiguity |
| Speed up research and first-pass analysis | Prioritize where to look and why |
| Crunch numbers and generate scenarios | Pull the key fact from fragmented sources |
| Produce fluent, plausible text | Hold a multi-step case together and own the call |
Read the right column again. It is a list of the skills a case interview is designed to measure. That is not a coincidence. The interview screens for the exact judgment the benchmark shows AI still lacks.

What This Study Does Not Mean
It is easy to over-read a benchmark, so be precise about what this shows and what it does not.
It does not mean AI is useless in consulting. The same models that fail whole tasks are genuinely good at the pieces, and firms are deploying them everywhere for exactly that reason. Dismissing AI because it scores 24% would be as wrong as claiming it will replace consultants tomorrow.
It does not mean the numbers stay here. Benchmarks are snapshots. Models improve, and the gap between assisting and doing the whole job will narrow, even if slowly. The honest read is “not yet and not soon,” not “never.”
And it does not mean your career is safe by default. AI is already reshaping the work and the hiring bar even though it cannot do the whole job. The data is a reason to prepare for a harder, higher-judgment version of consulting, not a reason to relax.
What it does mean is specific: today, AI cannot reliably own end-to-end consulting work, and human judgment is still the scarce, valuable thing.
What This Means for Your Consulting Career
If you are trying to break into consulting, this data is genuinely good news, and it comes with a condition. The good news: the human skill at the center of consulting is not going away, because AI cannot yet replicate it. The condition: firms now know competent-looking output is cheap, so they screen harder for the real thing.
That points to a clear plan. Build the judgment AI lacks, structuring ambiguous problems, prioritizing, and defending a recommendation, because that is what both the job and the interview reward.
For the career-anxiety version of this question, read our full take on whether AI will replace consultants. For how the shift is reshaping hiring and the entry-level role, see the article on AI’s impact on consulting careers and our guide to the junior consultant role in the AI era. And for where the industry is heading, the future of consulting.
The one-line version: AI raised the value of human judgment, so prepare to prove yours.
Can AI Do Consulting Work? FAQs
Can AI do consulting work?
It can do parts of it well, such as research, analysis, and drafting, but not the full job. Mercor’s 2026 benchmark found the best AI models completed under 25% of realistic consulting tasks correctly on the first try, because consulting requires end-to-end judgment AI cannot yet deliver.
Will AI replace consultants?
No clear evidence of that yet. AI automates tasks inside consulting, but it cannot own the ambiguous, multi-step, accountable work the role exists for. It augments consultants rather than replacing them. We cover the full answer in our guide on whether AI will replace consultants.
What is the Mercor APEX-Agents benchmark?
A 2026 test that measures whether AI agents can complete realistic professional tasks, not just answer quiz questions. It simulates real consulting workflows with documents, spreadsheets, and tools, and scores whether an agent finishes the whole task correctly.
How well do AI models actually do on consulting tasks?
Poorly, so far. On a first-try basis, the top models scored under 25%, and even with eight attempts the best reached only about 40%. On realistic consulting work, current AI fails most of the time on its own.
Why can’t AI do consulting work end to end?
Because it struggles with ambiguity, finding the key fact across fragmented sources, and holding context over long, multi-step work. Consulting is a chain of dependent judgment calls, and AI loses the thread and the accountability along the way.
Does this mean AI won’t affect consulting careers?
No. AI is reshaping the work and raising the bar, even though it cannot do the whole job. It automates production tasks, so firms expect more judgment sooner and screen candidates harder for the skills AI lacks.
Is the Mercor benchmark reliable, and who is Mercor?
Mercor is a research and expert-marketplace firm. It released the APEX-Agents benchmark, dataset, and scoring rubrics openly under a Creative Commons license so others can verify and build on the work. The tasks were designed with hundreds of experts from top firms, which is why they mirror real client work rather than quiz questions.
The Bottom Line
Can AI do consulting work? It can do the tasks and not the job. The best evidence we have, Mercor’s 2026 benchmark, shows top models failing three of four realistic consulting tasks on the first try, because the work is an end-to-end exercise in judgment and accountability that AI cannot yet own. AI is a powerful assistant, not a replacement for the consultant who frames the problem and stands behind the answer.
For you, that is the whole strategy in one line: the durable value is judgment, so build it and prove it.
About the author: Florian Smeritschnig is a former McKinsey Senior Consultant and the founder of StrategyCase. He spent five years at the firm and has since run more than 2,200 mock case interviews and coached hundreds of candidates into McKinsey, BCG, Bain, and other top firms.

